It’s a long story… an oddessey of almost two years…
But to start from the beginning: Back then I rented a server at Hetzner until they decided to bill for every IP address you got from them. I got a /26 in the past and so I would have to pay for every IP address of that subnet in addition to the server rent of 79.- EUR/month. That would have meant nearly doubling the monthly costs. So I moved with my server from Hetzner to rrbone Net, which offered me a /26 on a rented Cisco C200 M2 server for a competitve price.
After migrating the VMs from Hetzner to rrbone with the same setup that was running just fine at Hetzner I experienced spontaneous reboots of the server, sometimes several times per day and in short time frame. The hosting provider was very, very helpful in debugging this like exchanging the memory, setting up a remote logging service for the CIMC and such. But in the end we found no root cause for this. The CIMC logs showed that the OS was rebooting the machine.
Anyway, I then bought my own server and exchanged the Cisco C200 by my own hardware, but the reboots still happen as before. Sometimes the servers runs for weeks, sometimes the server crashes 4-6 times a day, but usually it’s like a pattern: when it crashes and reboots, it will do that again within a few hours and after the second reboot the chances are high that the server will run for several days without a reboot – or even weeks.
The strange thing is, that there are absolutely no hints in the logs, neither syslog or in the Xen logs, so I assume that’s something quite deep in the kernel that causes the reboot. Another hint is, that the reboots fairly often happened, when I used my Squid proxy on one of the VMs to access the net. I’m connecting for example by SSH with portforwarding to one VM, whereas the proxy runs on another VM, which led to network traffic between the VMs. Sometimes the server crashed on the very firsts proxy requests. So, I exchanged Squid by tinyproxy or other proxies, moved the proxy from one VM to that VM I connect to using SSH, because I thought that the inter-VM traffic may cause the machine to reboot. Moving the proxy to another virtual server I rented at another hosting provider to host my secondary nameserver did help a little bit, but with no real hard proof and statistics, just an impression of mine.
I moved from xm toolstack to xl toolstack as well, but didn’t help either. The reboots are still happening and in the last few days very frequent. Even with the new server I exchanged the memory, used memory mirroring as well, because I thought that it might be a faulty memory module or something, but still rebooting out of the blue.
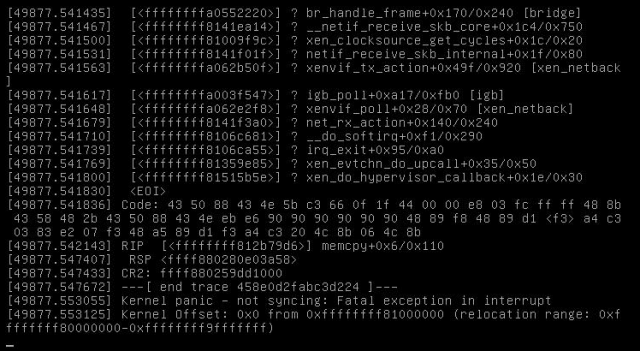
During the last weekend I configured grub to include “noreboot” command line and then got my first proof that somehow the Xen network stack is causing the reboots:
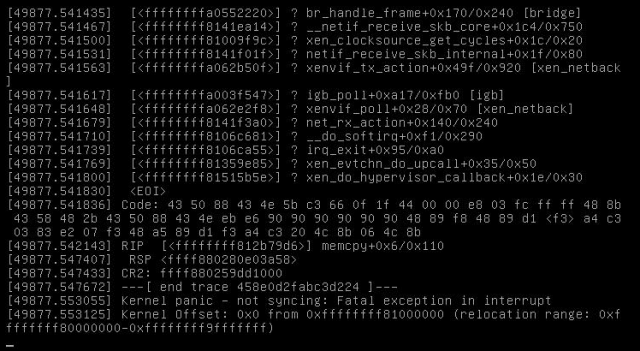
This is a screenshot of the IPMI console, so it’s not showing the full information of that kernel oops, but as you can see, there are most likely such parts involved like bridge, netif, xenvif and the physical igb NIC.
Here’s another screenshot of a crash from this night:
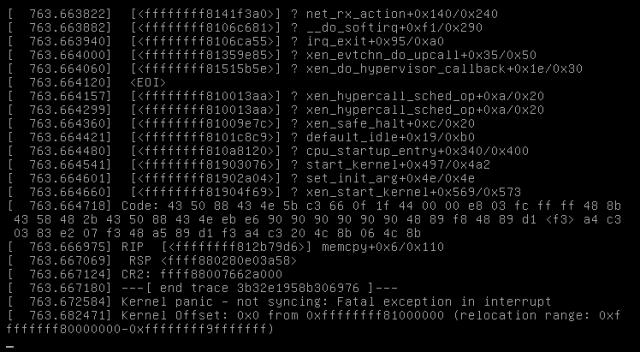
Slightly different information, but still somehow network involved as you can see in the first line (net_rx_action).
So the big question is: is this a bug Xen or with my setup? I’m using xl toolstack, the xl.conf is basically the default, I think:
## Global XL config file ##
# automatically balloon down dom0 when xen doesn’t have enough free
# memory to create a domain
autoballoon=0# full path of the lockfile used by xl during domain creation
#lockfile=”/var/lock/xl”# default vif script
#vif.default.script=”vif-bridge”
With this the default network scripts of the distribution (i.e. Debian stable) should be used. The network setup consists of two brdiges:
auto xenbr0
iface xenbr0 inet static
address 31.172.31.193
netmask 255.255.255.192
gateway 31.172.31.254
bridge_ports eth0
pre-up brctl addbr xenbr0auto xenbr1
iface xenbr1 inet static
address 192.168.254.254
netmask 255.255.255.0
pre-up brctl addbr xenbr1
There are some more lines to that config like setting up some iptables rules with up commands and such. But as you can see my eth0 NIC is part of the “main” xen bridge with all the IP addresses that are reachable from the outside. The second bridge is used for internal networking like database connections and such.
I would rather like to use a netconsole to capture the full debug output in case of a new crash, but unfortunately this only works until the bridge is brought up and in place:
[ 0.000000] Command line: placeholder root=UUID=c3….22 ro debug ignore_loglevel loglevel=7 netconsole=port@31.172.31.193/eth0,514@5.45.x.y/e0:ac:f1:4c:y:x
[ 32.565624] netpoll: netconsole: local port $port
[ 32.565683] netpoll: netconsole: local IPv4 address 31.172.31.193
[ 32.565742] netpoll: netconsole: interface ‘eth0’
[ 32.565799] netpoll: netconsole: remote port 514
[ 32.565855] netpoll: netconsole: remote IPv4 address 5.45.x.y
[ 32.565914] netpoll: netconsole: remote ethernet address e0:ac:f1:4c:y:x
[ 32.565982] netpoll: netconsole: device eth0 not up yet, forcing it
[ 36.126294] netconsole: network logging started
[ 49.802600] netconsole: network logging stopped on interface eth0 as it is joining a master device
So, the first question is: how to use netconsole with an interface that is used on a bridge?
The second question is: is the setup with two bridges with Xen ok? I’ve been using this setup for years now and it worked fairly well on the Hetzner server as well, although I used there xm toolstack with a mix of bridge and routed setup, because Hetzner didn’t like to see the MAC addresses of the other VMs on the switch and shut the port down if that happens.
openvswitch
why don’t you just use openvswitch – it’s very fast and has tons of advanced features…
openvswitch doesn’t change anything
as i wrote in a comment to the bloggers follow-up blogpost, i’m having this crash, too.
but: i use openvswitch, no regular bridge – so that doesn’t change anything obviously
Alsio experiencing crashes
You didn’t tell which Linux-Distribution and Xen-Version you’re using.
We’ve beer running xen-4.1.3 with Linux-3.10 fine, but I’ve also seen crashes after an upgrade to xen-4.1.6 (Ubuntu-bases) and Linux-3.16. The crash occurs if I live-migrate a VM from a host running the new xen+linux to a host running the old xen+linux. Doing a non-live-migration or migrating in the reverse directions seems to work fine.
I’ve not yet been able to capture a crash dump, but my problem also seems to be network related.
Oh, I’ve mentioned that I’m
Oh, I’ve mentioned that I’m running Debian stable. Also no migration is involved, but good to know that other users experience similar problems. Saving the crash dump is, of course, another option to investigate this issue… 🙂
netconsole equivalent
Long ago, I built an automation plugin for this cause only. Back then, I was working with storage vendor and my focus was Linux storage.
The thing with storage is, if the kernel bug triggers, even the logs are lost. And on networked storage, Storage + Network bugs are common. And not to forget Scheduler and Memory bugs too.
So your ultimate goal is to have a network channel to pass of the kernel oopses to another box for analysis. And netconsole doesn’t help because, from what you’ve mentioned, is not taking a bridge interface.
Assuming your Debian setup is able to boot full before the bug is triggered, you could do something like the following:
test machine: `nc -l 9009 < /proc/kmsg` log machine: `nc test-machine:9009` That should carry your logs. You can extend this basic with any framework you like.
Hi Ritesh!
Hi Ritesh!
Thanks for your comments! Luckily there’s another NIC not being part of the bridge setup I could use for netconsole and the colocation provider is willing to connect that second NIC to the network and allow traffic to one of my other servers.
So, to my knowledge this should then help in debugging this issue as I would (hopefully) get all of the kernel oops output, right?
Only problem so far is: the machine runs now stable for >30 days without a crash… 😉