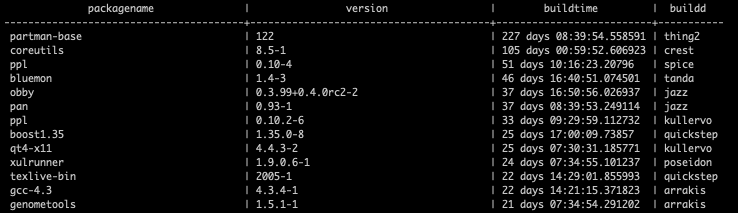
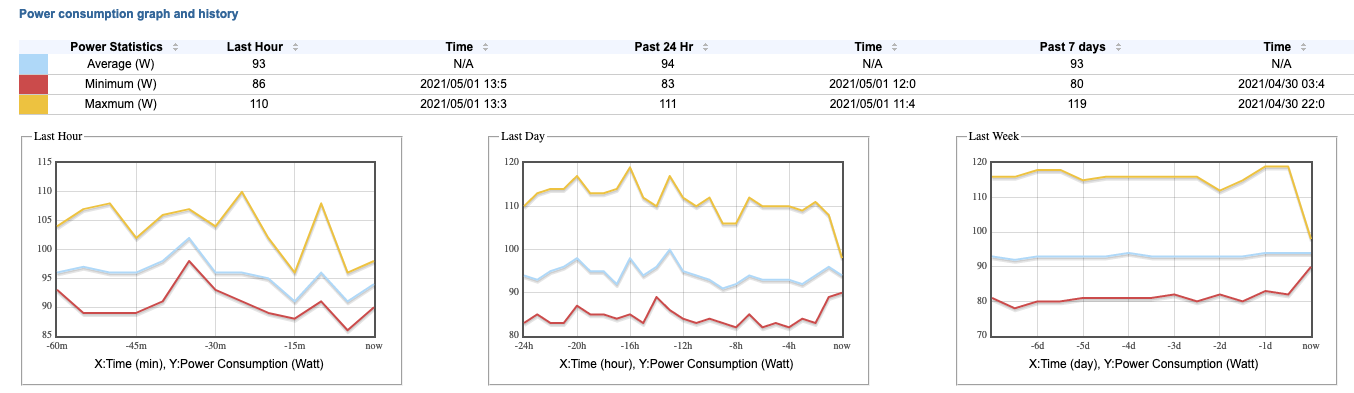
Outages on Nerdculture.de due to Ceph
Well, maybe it’s not entirely correct to blame Ceph for outages that happened in the last weeks to Nerdculture.de and other services running on my servers, but, well, I need to start somehow… Overview Shortly after the update from Debian… Read moreOutages on Nerdculture.de due to Ceph