Well, maybe it’s not entirely correct to blame Ceph for outages that happened in the last weeks to Nerdculture.de and other services running on my servers, but, well, I need to start somehow…
Overview
Shortly after the update from Debian 12 “Bookworm” to Debian 13 “Trixie” I also updated the Debian-based Proxmox installations. And then the issues began and I had sleepless nights, many downtimes and frustrated users, because the usually rock-stable Ceph storage became unstable. The OSDs went off the net, the Ceph Filesystem got degraded and everything became slow. The Ceph Filesystems (CephFS) also holds the mail storage as well as the shared storage (code & data) for my Nerdculture.de Mastodon instance.
Just to outline what I’m about to discuss, here’s the cabling plan for my 3-node hyperconverged Proxmox server setup:
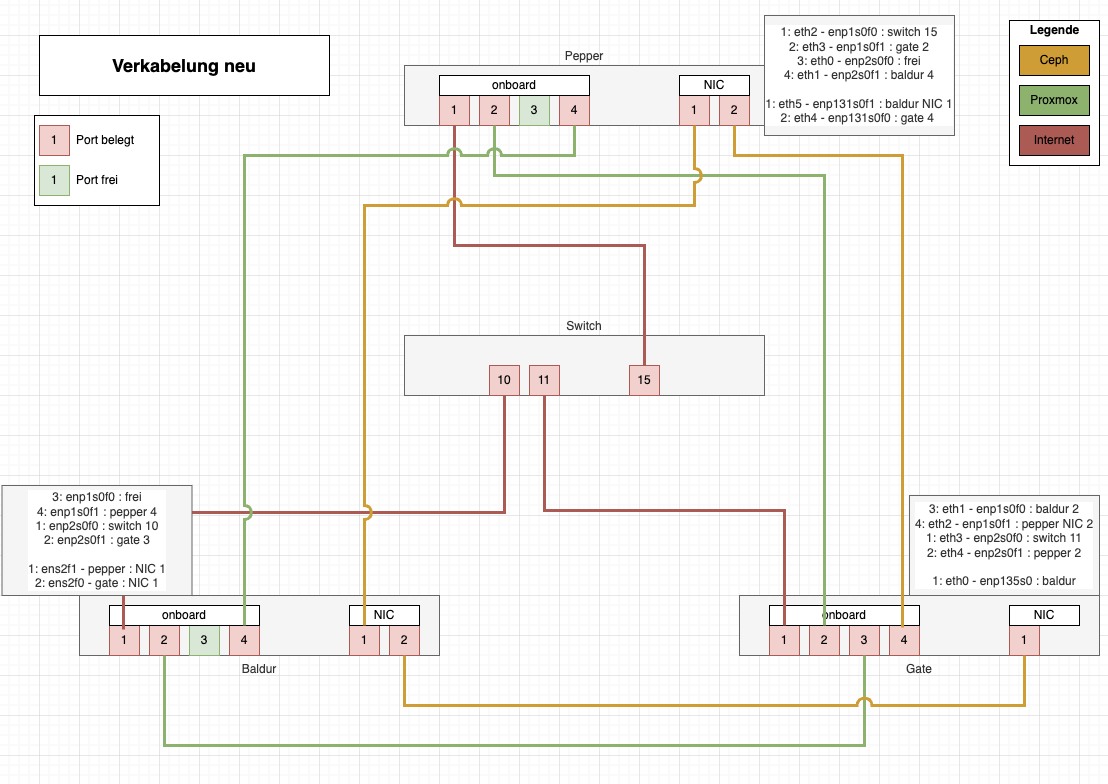
Basically you see 3 types of connections:
1) Internet connection to the colocation switch
2) Internal Proxmox connections between the 3 nodes
3) Internal Ceph connections between the 3 nodes
The internal, directly wired connections are necessary because the colocation provider have had no additional Copper 10 Gbit/s ports (10GbaseT) available. So I had to wire up all those by directly attached patch cables.
Ceph has a backend and frontend network. You can run Ceph with just one network, but well, then Proxmox and Ceph would need to share the same network and access to Ceph would slow down when Virtual Machines (VMs) were migrated between the nodes.
What happened the last weeks?
The problem started, as said, after updating the Proxmox nodes. On Sept. 24th the first outage happened. You can read my summary here. Somehow the network Ceph connection between didn’t work anymore. The setup that was running for years now didn’t work anymore. The Ceph backend network couldn’t see the disks (OSD) any longer, so added manual routes between the nodes instead of relying on FRR with OSPF (a dynamic routing protocol). This solved the problem back then.
The next issue happened a week later on Oct. 2nd: since the last issue a week before I discovered that CephFS was awkfully slow. Loading the mails took like 10 seconds instead of being instantly there. So I tried to find the reason. My best assumption was: the WD Red SA500 2 TB that are holding the WAL/DB for the Ceph cluster are reaching the wear level end. These SSDs are not made for that kind of workload.
Another reason might be that the Ceph frontend network, which uses the Proxmox network, because the VMs need to access the Ceph frontend, is a OpenVSwitch bridge and traffic from Baldur is using the link via Pepper to Gate, for example, instead of using the direct connection, which adds some latency and reducing bandwidth.
And with that being said, this was the reason why there was an outage yesterday as well:
For the Ceph backend network, I use an internal Linux bridge in Proxmox to hold the IP for the Ceph backend on each node. Then there are two network cards, as described in the drawing. On the link between the nodes I configured Point to Point connections and added a route for the direct neighbor with a lower metric and a route for the other node with a higher metric. The other link vice versa. This works pretty well for the Ceph backend.
Yesterday I wanted to deploy those changes as well to the Proxmox network and get rid off of that Layer 2 network via OpenVSwitch. Settings this up in the operating system was no big deal, but unfortunately Proxmox complained later about the nodes having more than one IP. And there the issue started again.
But there was another problem, because even when reverting that network change, the Ceph cluster had issues again and couldn’t find its peers. I restarted services, rebooted nodes, etc… whatever to make it work again. But still OSDs were failing, coming online again, and failing again. The service mnt-pve-cephfs.mount was not able to mount the CephFS and thus CephFS was not available for the VMs and therefore the services like mail and Mastodon failed to load as well as nearly all services that need SSL certificates which – you guess it! – lies on CephFS as well. No CephFS available, no SSL certs and no service.
But why was it not possible to mount the CephFS on the Proxmox host nodes? I had a look onto the syslog and other logs while restarting services, but the output was that much and fast, that I couldn’t find the root cause for it.
At one time I was lucky and spotted this line: 2025-10-12T01:05:28.209050+02:00 baldur ceph-mgr[40880]: ERROR:root:Module 'xmltodict' is not installed.
And the solution was as simple as searching the web for that error message and stumble across this post in the Proxmox forum:
I was able to correct this with python3-xmltodict, that resolved one issue
So, after installing that package the Ceph cluster was happy again and Proxmox could finally mount CephFS with restarting mnt-pve-cephfs.mount.
Then it was just a matter of restarting VMs and services and finally Mastodon on https://nerdculture.de/ was available again as well as mail started to come in.
Lessons learned
For one I’m going to buy new SSDs for WAL/DB in Ceph, most likely Micron 5400 MAX. This should bringt he latency down with Ceph and increase the overall speed, because data is only written for the client, when all 3 nodes have written their data to disk. The slowest node or disk is the resulting speed of Ceph. WD Red SSDs might be good enough for NAS systems, but for constant disk writes like in the case of WAL/DB in Ceph, they seem to hit their limit rather soon.
Another thing I could improve is the network. It is a complex setup and prone to errors. I need to talk to the colocation if I can get 6x 10 Gbps ports on their switch or if I can bring in my own switch and what that would cost?
Speaking of: what switch would you recommend?
Haha, what a rollercoaster ride through the Ceph underworld! From network routes to worn-out SSDs and a Python library drama – youve seen it all. Buying new SSDs sounds like a good plan, though I suspect the real villain might be Proxmoxs mysterious IP complaints. And upgrading to 10 Gbps sounds grand, as long as the colocation isnt charging extra for network agility. Keep fighting the good fight, and maybe next time, the logs wont lead you on such a wild goose chase. All the best getting Mastodon back up!vongquaymayman